

Nous canalisons des millions de lignes de données dans un pipeline, éliminons le bruit et permettons aux entreprises de générer des résultats exploitables.
C’est le parcours d’une équipe de science des données qui construit des Attributs, un outil qui donne du sens — et de l’impact — aux données transactionnelles brutes.
Au début, il y avait une grosse pile de données
Des centaines d’entreprises utilisent nos outils de données financières pour construire et alimenter des produits financiers. Les équipes d’ingénierie et de science des données ici chez Flinks travaillent d’arrache-pied pour rendre les données accessibles par agrégation et significatives par l’enrichissement.
Nous avons déjà entrevu ce à quoi ressemble l’avenir de la finance pour les consommateurs : des services financiers qui les ravissent avec des expériences personnalisées incroyables.
C’est facile d’être d’accord. Y arriver, c’est une toute autre histoire.
À mesure que tout devient connecté, les données devraient alimenter les processus, les produits et les expériences. L’historique transactionnel des consommateurs, en particulier, est facilement accessible et contient une mine d’informations sur le profil financier et le comportement d’une personne. Pourtant, les entreprises financières, les banques et les fintechs, peinent encore à extraire de la valeur de ce qui est souvent un chaos de données.
Il y a de la valeur dans les données transactionnelles. Alors, comment l’extraire?
Chaque fois que vous voulez résoudre un problème complexe, vous devez commencer par une première étape. Le nôtre nous a permis de mettre les pieds dans un nouveau territoire passionnant : la création d’Attributes, un outil d’enrichissement de données conçu pour être flexible et dynamique afin de pouvoir être appliqué à tous les scénarios où les entreprises doivent mieux comprendre leurs clients.

Concrètement, nous leur permettons de fouiller dans des millions de lignes d’historique des transactions et d’extraire des attributs complexes de données qui alimentent leurs modèles ou permettent à leurs experts de prendre des décisions plus rapides et éclairées. Et franchement, ça ressemble à des superpouvoirs.
Obtenir de l’énergie à partir des données
Dans l’ensemble de l’industrie, la catégorisation des données transactionnelles sert principalement à améliorer l’expérience des utilisateurs finaux. Les applications de gestion financière personnelle s’appuient fortement sur cette technologie pour apporter de la valeur à leurs utilisateurs en leur donnant visibilité et perspective sur leurs transactions. Améliorer les données transactionnelles à un niveau granulaire, comme ajouter de l’information sur la localisation du fournisseur, est logique dans ce contexte.
La direction que nous avons prise avec Attributes aide nos clients à améliorer leurs processus d’affaires.
En ce moment, beaucoup d’entre eux comptent sur le travail manuel pour manipuler les données : si un prêteur veut savoir combien de frais NSF un client a eu l’année précédente, quelqu’un doit passer manuellement au peigne fin les relevés bancaires pour les identifier et les compter. Même des opérations très simples sont fastidieuses — ce qui signifie qu’il y a de la place pour innover et les rendre plus rapides et précises, voire les automatiser.
Pour extraire de la valeur des transactions, nous devions créer un outil permettant de manipuler de grandes quantités de données et de les résumer en attributs de données consommables. Les attributs de données sont essentiellement des fonctions personnalisées qui agrégent des données pour répondre à des questions spécifiques. Quelques conseils assez simples : combien de frais NSF l’utilisateur final a-t-il reçus au cours des 12 derniers mois? C’est très complexe : l’utilisateur final a-t-il eu des activités irrégulières de compte récemment?
Chaque attribut de données révèle un aspect du profil financier et du comportement des consommateurs d’un utilisateur final.
Un seul attribut de données éclaire un aspect très spécifique du profil financier d’un utilisateur final — mais pris ensemble, les attributs des données créent une vue globale et précise. L’objectif était de permettre à nos clients d’utiliser les attributs des données comme des blocs de construction, afin de structurer facilement l’outil spécifique d’enrichissement des données qui correspond à leur contexte. Les deux principes fondamentaux de conception qui ont guidé la création des Attributs sont la flexibilité et le dynamisme.
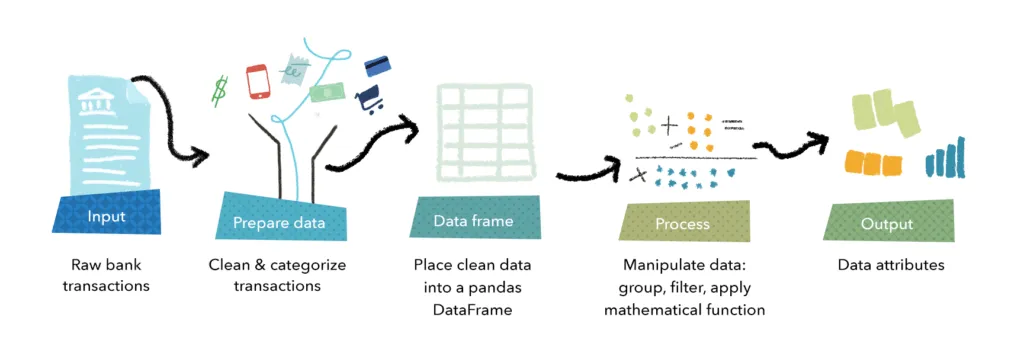
Jouer avec les pandas (DataFrames)
L’entrée des attributs est constituée de données transactionnelles brutes. Nous recueillons les données transactionnelles des utilisateurs finaux grâce à l’agrégation de comptes. Rangées et rangées de dates, quantités et descriptions. C’est un ensemble de données désordonné et bruyant que nous devons nettoyer et catégoriser.
Petite parenthèse : la catégorisation des données est un sujet incroyablement fascinant et profond qui mérite vraiment sa propre histoire — alors gardons ça pour une autre fois. Pour l’instant, disons simplement que nous trions les transactions et appliquons des étiquettes qui les décrivent : est-ce revenu ou dépense, quelle est la source ou la destination, etc.
Nous plaçons ensuite ces données catégorisées dans un DataFrame pandas. C’est un outil puissant qui nous permet d’organiser les données en lignes et colonnes. Pensez à un tableau Google conçu pour les programmeurs Python.
L’élément de flexibilité d’Attributes provient de l’utilisation de DataFrames pandas pour structurer et manipuler les données.

Cela nous permet de créer des fonctions personnalisées pour interagir avec les données sous-jacentes. De la même manière que les analystes de données manipulent, transforment et résument les données dans un tableur, notre équipe de science des données est capable de manipuler, transformer et résumer des données à l’aide de pandas DataFrames.
Nous pouvons construire des fonctions pour effectuer des calculs complexes de façon répétable — ce qui fait du DataFrame un excellent choix pour créer des attributs de données. Et puisque tous les calculs se font en mémoire, ce processus est globalement très rapide.
Construire les blocs de construction
Nous avons initialement commencé avec un cadre très basique pour la manipulation des données — des opérations de base comme filtrer les colonnes et appliquer des fonctions mathématiques (somme, min, max, compte) pour générer des sorties agrégées. C’était un bon point de départ, car cela nous a permis de saisir les subtilités des données, ce qui nous a donné une base solide sur laquelle bâtir.
L’élément dynamique d’Attributes vient de la capacité à créer des fonctions de plus en plus complexes pour manipuler les données de manière plus subtile — et répondre à des questions très complexes.
En explorant davantage les besoins de nos clients, nous avons découvert qu’il fallait employer des fonctions plus complexes pour gérer des situations réelles. La façon la plus naturelle pour nous d’aborder cela a été d’ajouter des fonctions impliquant la capacité de filtrer plusieurs colonnes, de regrouper des catégories et d’appliquer des fonctions périodiques temporelles aux distributions de catégories.
En ajoutant ces fonctions à notre cadre, nous sommes capables de combiner et de traiter avec précision des millions de lignes de données transactionnelles de façon agrégée pour générer des attributs de données. Encore mieux, nous sommes maintenant en mesure de combiner des attributs individuels des données pour générer des métriques avancées et analyser les tendances.
Prenons la pizza comme exemple.
(On est vraiment de grands fans de pizza.)
Plutôt que de simplement se concentrer sur la somme des dépenses de pizza, nous pouvons maintenant répartir les catégories autour de la pizza plus efficacement. Combiner Pizza Spend avec, disons, Payroll Income, donnerait des informations détaillées sur la relation entre les deux. Ou peut-être qu’une comparaison entre les dépenses récentes de pizza et les revenus historiques serait préférable, répondant à des questions telles que :
- Si mon client commence à gagner plus d’argent, est-ce qu’il achète plus (ou moins) de pizza?
- Si mon client a eu une augmentation de salaire il y a deux mois, est-ce qu’il finit par dépenser plus d’argent en pizza en ce moment?
Quelle est la bonne question? Tout dépend du contexte spécifique du client. L’avantage, c’est que nous pouvons bâtir sur nos bases actuelles pour faire face à de nouvelles situations.
J’ai hâte
Nous voilà donc, ayant franchi les premières étapes pour aider les entreprises financières à donner du sens et de l’impact à leurs données.
Dès le départ, notre vision a été de faciliter l’analyse des données transactionnelles.
Jusqu’à présent, nous avons gardé le contrôle sur la création des attributs de données afin d’assurer une compatibilité complète avec notre cadre. L’étape naturelle suivante, que notre équipe de science des données est enthousiaste à l’idée d’explorer, est d’ouvrir ce processus à nos clients et de leur confier cette fonctionnalité directement.
.png)

